
(This article is an excerpt of Chapter 5 from the book “Tech Fluent CEO” — a new breakthrough book for non-technical people who want to build and lead digital companies.)
In most system diagrams, a database is depicted as a cylinder (as shown in the figure) that just sits there as an opaque black box, simply storing data.
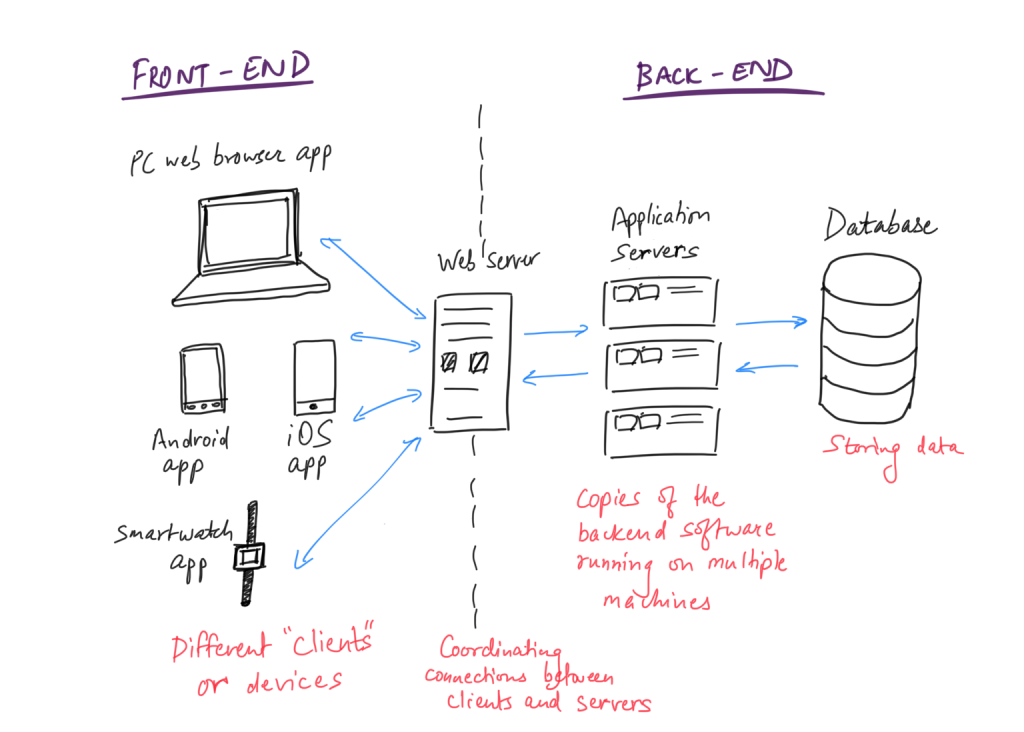
(Looking forward to your fan letters for my award-winning drawing and calligraphy skills.)
In reality – and you might laugh at me for saying this – modern database systems are so cool and sophisticated that I almost see them as living, breathing, constantly evolving digital creatures. They’re the backbone of the digital world, and of your company too.
I can give it to you in writing that at least once in your business journey, you’ll want to do something with your application such that an engineer will say, “well, the database isn’t set up that way, but it’s hard to explain why.” A bad database setup is not only expensive to fix later but also a pain in the ass for whoever has to deal with it. So let’s give databases the deep dive they deserve.
First, we will build a software system for managing a traditional school library.
Georgina Borrows A Book
Here’s a use case: Georgina borrows a book. Let’s follow the story.
Georgina enters the library, looks around, and picks up a book she likes (Shoe Dog). She goes to the lending desk, where Hiroko is working and says “I’d like to borrow this book!”
Hiroko asks Georgina if she has a membership card. She also needs to know if Georgina has any books overdue, if she has already borrowed her max number of books, etc.
Georgina says, “I don’t have my card, but my phone number is 555-1234.”
So here’s our first set of requirements: The software shall have information about every library member. It shall allow us to search this data with multiple keys like phone number, membership number, etc. It shall also show a member’s history of borrows and returns.
Say Georgina is all clear. Hiroko makes a new entry into the software that Georgina borrowed Shoe Dog.
The software shall have a catalog of all library books. It shall also allow making new entries that update a book’s status and link it to a member.
Let’s say the library’s marketing team also has questions – they want to know which books are most popular, etc. So we also want to easily search the entire history of a book (who all have borrowed it and how long they kept it etc).
The Classic Way
Personally, I grew up going to non-digital libraries. In case you did not have the same experience, here’s a quick description of how they worked:
Each book had a little paper pocket glued inside the cover, with a small card inside it. When you borrowed a book, they’d remove this card, put the date and your name and ID on it, and keep it with them. They also had thick registers full of members’ information. (I suspect they also had lists of all the books in the inventory but didn’t keep it up-to-date.)
So at any given time, they had a stack of cards from all the books that had been borrowed. If you were late in returning the book, they could easily look up your phone/address from the register and send you a reminder. When you returned the book, they’d scratch out your name on the card and put it back in the paper pocket.
It’s optimised for one objective – making sure that books get returned on time – and it’s pretty effective at that. I loved the simplicity and elegance of this arrangement.
But let’s say the library’s marketing team came up with a question. (I only learned while writing this book that some libraries actually do have marketing teams. The more you know!) Consider this query: “Which were our five most popular books in the last year?”
In libraries that use the paper pocket system, this is a horribly difficult question to answer. It would take you several days (or maybe weeks) to search through the borrowing history of all the books.
To answer it quickly, you would have to organise the information in a totally different way – but that may have implications on how easy it is to track overdue books, etc. Or, you could make copies of the same data in different formats, to answer different types of queries.
Does that make conceptual sense? We’ll come back to this later.
Database Schemas
Coming back to the software, would you organize all the raw data? Say you used simple spreadsheets. What different tables would you have to make, and which columns?
These design details are called your “schema” (pronounced ‘ski-ma’).
Here’s a possibility:
Table 1: Members
| NAME | MEMBER ID | PHONE | MEMBER SINCE | BOOKS LIMIT |
| Georgina | 87651 | 555-1234 | Aug 11, 2019 | 3 |
| Abdul | 44320 | 656-1255 | March 07, 2017 | 3 |
Table 2: Books
| BOOK TITLE | BOOK ISBN | DATE ADDED | BOOK ID |
|
Shoe Dog |
####87 | Jan 12, 2019 | AU-01 |
|
Honoring the Self |
####09 | Oct 22, 2019 | NF-99 |
| Thinking Fast and Slow | ####11 | Apr 30, 2017 |
EC-34 |
Table 3: Transactions
| MEMBER ID | BOOK ID | TYPE | DATE |
| 87651 | NF-99 | Borrow | June 1, 2020 |
| 87651 | EC-34 | Return | May 1, 2020 |
| 44320 | NF-99 | Return | April 25, 2020 |
| 87651 | EC-34 | Borrow | April 15, 2020 |
The Transactions table’s entries link the previous two tables, Members and Books.
The above tables don’t look beautiful so you may not have paid much attention to them (if I was in your place, I would have glossed over ugly tables with numbers too). But they’re important and quite simple, so I won’t let you get away easily! Let us follow the transaction in more detail:
I. Searching for Georgina’s information: We look up the phone number in the Members table and see if the rest of the information (Name, etc) matches with the person.
| NAME | MEMBER ID | PHONE | MEMBER SINCE | BOOKS LIMIT |
| Georgina | 87651 | 555-1234 | Aug 11, 2019 | 3 |
We see that Georgina does exist in our database, and has a limit of borrowing up to 3 books at a time.
II. Checking if Georgina has any overdue books: Hmm, this seems tricky. Let’s search the Transactions table with Georgina’s member ID (87651). We see the following:
| MEMBER ID | BOOK ID | TYPE | DATE |
| 87651 (G) | NF-99 | Borrow | June 1, 2020 |
| 87651 (G) | EC-34 | Return | May 1, 2020 |
| 87651 (G) | EC-34 | Borrow | April 15, 2020 |
Notice that this table acts as a ‘link’ between Members and Books.
So it seems like we have 3 entries: Georgina borrowed and returned a book previously, and currently has one book (NF-99, or Steal Like An Artist) that she hasn’t returned.
Now, we need to decide if that book is overdue or not. You may not have realized this, but our schema doesn’t yet include a way of telling this!
- Should we have an extra column in the Books table, saying how long each book can be borrowed?
- Or should this apply to Members instead (different members can borrow books for different durations depending on how much they paid, perhaps)?
- Should it simply be a fixed duration for all books and all members, removing the immediate need for storing it in the database?
These are highly contextual non-technical / business decisions, but they directly influence how the database schema would be designed.
It’s quite hard to change the database schema once it has been set up, so it should be done with care. It’s not unusual for people to be forced to recreate a database from scratch and spend a few days copying and reproducing all the data.
Moreover, notice that I kept the Transactions separate from the Members and Books tables. When someone borrows or returns a book, I don’t want to add that information into a new column or row in the Members or Books tables. Keeping information separate allows us to keep things clean! This is an example of a best practice. Engineers have many best practices for designing database schemas so they are less likely to have issues.
III. Making new entries, and asking complex questions: When we let her borrow Shoe Dog, we make one more entry to the Transactions table. Later, when she comes back and returns it, we’d add another entry to the same table. This way, we can store much better records about the Library’s operations. It also enables us to answer more intelligent questions such as:
-
- “Which are our 5 most popular books? We may want to order more copies.” -> Simply go through the transactions table and count which book IDs appear the most often.
- “Who are our 10 most active members from the last month? We want to send a gift.” -> Look at which member IDs appeared the most often in the transactions table.
- “Of all the members that have ever borrowed Shoe Dog, how many of them have been members for at least a year?” -> You would have to cross-relate data from all three tables, but it’s not too complicated.
Just by changing the way information is stored, these queries went from being notoriously difficult to answer, to being very easy and straightforward!
You can probably see that there is no right or wrong answer for how to design the best schema for a particular database. The schema depends on the goals of the organization. A bank, a hospital, a library, etc all have very different data needs and have to answer different types of queries on a daily basis, so the schemas are unique.
In finance and accounting, everybody uses double-entry bookkeeping. It is a format for recording transactions and involves having two columns in a ledger instead of a single column. Unless you’ve dabbled in finance, this may not seem like a very powerful example to you. But without this two-column schema, even simple queries like calculating monthly profit and loss is a tedious and tiresome task. Double-entry ledgers were independently invented in different places throughout history, but really exploded in popularity in the 1400s, when an Italian monk wrote a book on the subject and turned accounting into a science. A simple change in how you record transactions made doing business so easy, that it helped propel our world into the golden age of modern finance – one we’re still living in.
I find that fascinating. By the way, did you know that the oldest surviving records of humans doing math, by making inscriptions on clay tablets and bones, are all related to accounting? Our ancestors only cared about abstract concepts like adding and subtracting numbers as long as it helped them figure out how much money they’re owed by their neighbor, or how much inventory they needed. (I do wonder how modern imaginary numbers like √-1 would have been received in those days.)
Quick recap:
- You have two basic types of operations with data: reads and writes.
- Depending on the application, you decide:
-
- What types of information you need to store in the database
- The kinds of queries that would be performed against that data
- Based on the above, you decide your database schema. Even though there are no right/wrong answers, there are always best practices you can follow while developing a new schema for a given purpose.
Relational/SQL Databases
What you saw above is called a relational database (RDB). Its schema has tables with rows and columns. Each entity (Member, Book, Transaction, etc) has its own separate table.
Then you have commands to select, insert, update or delete data. All these are different types of queries. Because these relational databases have a strict, structured schema chosen carefully at the beginning, they need you to use a structured query language (SQL) to look up information. You can manipulate thousands (if not millions) of rows of data with a single line of SQL code. SQL is scary – if you make a big mistake that updates thousands of rows, there is no simple way of undoing a change to a database. But, for the same reasons, it is also a very powerful language.
In fact, SQL is so popular that relational databases are also referred to as SQL databases! They store all the information in tables with fixed columns, which can run into billions of rows. In SQL databases, the data is more consistent and reliable. This makes it easier to read (or look up) information. A lot of financial organizations use SQL databases at the core. Having strict schemas lets them be more careful about what they are writing to their database (adding new entries or modifying/deleting existing ones), and helps keep the integrity of the data.
But like most other things in this world, nothing is perfect. There are also some problems with SQL databases, which we’ll discuss next.
This article is an excerpt of Chapter 5 from the book “Tech Fluent CEO” — a new breakthrough book for non-technical people who want to build and lead digital companies.


